2020年病毒带来的恐慌对大多数人来说是不平淡的一年.于我个人而言,翻开2019年的总结,好惭愧好多事情没有做.
带着惭愧做一下2020年的反思和打算
驾照没有考,前半年新冠严重不敢去,加上宝宝出生,也就没有想去考的想法了.
旅游没有去.新冠肆虐可以算借口,不过今年是真的没有想法,也是因为太穷了.
个人读书方面,每月三本的读书没有完成,大概每个月能读1-2本的书.技术的书算是比较少,多的是一些科技人文方面的技术书籍.大多的书是通过微信读书这个APP和纸质书来读的,以前用Kindle、微信读书等一些app,现在重度的用微信读书APP,偶尔也可以听书的.
每月2篇的技术文章没有坚持完成,其实是没有以前那么热衷于技术了.也许是内心容易浮躁.一直尝试给自己找理由找借口,希望今年能持续改进了.
技术学习方面用的极客时间app上面买了不少课程,大概今年学完了有三四门课程.
上半年家里也发生了很多事情,都是些家常里短的事情,爷爷去世了,对我的冲击较大.很长时间才走出内心的阴霾.
当然开心的事情也有.
上半年宝宝出生了.我也成外了超级奶爸,肩上的担子重了.当然每天回家也是很开心快乐的.奶孩子是一件累并快乐的事情.
在家里人各种支持和救济的情况下,拼了老命在上海买了房子,想想看房这么久,都快成看房专家了.一路的艰难历程都能写本小说了.也从一个房产小白慢慢的知道里面的弯弯套套的.现在更是负债累累,努力拼命搬砖.
随着年龄的增长,脾气也是以暴易怒,经常莫名其妙的发火,之前看过一篇文章说,发火是因为自己的胸怀不够,不能正视自己的问题,应该多读书,能够坦然面对自己的不完美,接受生活中缺陷.
感情方面.偶尔有争吵.大多是鸡毛蒜皮的琐碎事情.多锻炼自己的心态,多耐心.
健身事情断了大半年,在体重持续并且油腻的情况之下,又重新拾起来了,经历的越多,越觉得身体是革命的本钱.没有好的身体一切都是浮云.
快年底的时候家里人来了一次上海,算是对2020年的结尾划上了一个句号.
2021年想想也没有大的目标.
小沐沐能健康快乐的成长,給足陪伴的时间.
多陪太太走一走逛一逛.至于旅游看疫情的控制吧.
多看点书,自己监督自己,每月2-3本吧😄,因为大家都知道读书是好事情,但是坚持的时候,缺很难做到.
争取每月1-2篇技术blog的输出,能发到博客和公众号.想把自己多年注册未用的公众号给用起来,尽量尝试一下.算是锻炼自己的写作能力.
万年不变的还是坚持健身,肚子瘦下来.弄点肌肉出来.可以秀起来💪.
有时间就去弄个驾照,看缘分也是不规划了.
有时间多撸点代码,算是锻炼智商了.
就这样吧.
Linux性能优化(一)
如何理解平均负载
uptime # uptime root@iZbp14ipzpabr30yllskn4Z 14:37:58 up 403 days, 1:48, 4 users, load average: 0.74, 0.63, 0.60 ~ # 而最后三个数字呢,依次则是过去 1 分钟、5 分钟、15 分钟的平均负载(Load Average)。 平均负载 平均负载是指单位时间内,系统处**于可运行状态和不可中断状态**的平均进程数,也就是**平均活跃进程数**,它和 CPU 使用率并没有直接关系。这里我先解释下,可运行状态和不可中断状态这俩词儿。 所谓可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。 不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
既然平均的是活跃进程数,那么最理想的,就是每个 CPU 上都刚好运行着一个进程,这样每个 CPU 都得到了充分利用。比如当平均负载为 2 时,意味着什么呢? * 在只有 2 个 CPU 的系统上,意味着所有的 CPU 都刚好被完全占用。 * 在 4 个 CPU 的系统上,意味着 CPU 有 50% 的空闲。 * 而在只有 1 个 CPU 的系统中,则意味着有一半的进程竞争不到 CPU。 查看CPU个数 [root@VM-64-25-centos ~]# grep 'model name' /proc/cpuinfo | wc -l 8 [root@VM-64-25-centos ~]# 平均负载为多少时合理 * 如果 1 分钟、5 分钟、15 分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。 * 但如果 1 分钟的值远小于 15 分钟的值,就说明系统最近 1 分钟的负载在减少,而过去 15 分钟内却有很大的负载。 * 反过来,如果 1 分钟的值远大于 15 分钟的值,就说明最近 1 分钟的负载在增加,这种增加有可能只是临时性的,也有可能还会持续增加下去,所以就需要持续观察。一旦 1 分钟的平均负载接近或超过了 CPU 的个数,就意味着系统正在发生过载的问题,这时就得分析调查是哪里导致的问题,并要想办法优化了。 那么,在实际生产环境中,平均负载多高时,需要我们重点关注呢? **在我看来,当平均负载高于 CPU 数量 70% 的时候,**你就应该分析排查负载高的问题了。一旦负载过高,就可能导致进程响应变慢,进而影响服务的正常功能。 **但 70% 这个数字并不是绝对的**,最推荐的方法,还是把系统的平均负载监控起来,然后根据更多的历史数据,判断负载的变化趋势。当发现负载有明显升高趋势时,比如说负载翻倍了,你再去做分析和调查。 平均负载与 CPU 使用率 现实工作中,我们经常容易把平均负载和 CPU 使用率混淆,所以在这里,我也做一个区分。 可能你会疑惑,既然平均负载代表的是活跃进程数,那平均负载高了,不就意味着 CPU 使用率高吗? 我们还是要回到平均负载的含义上来,平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。 而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如: * CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的; * I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高; * 大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。 平均负载案例分析 我们以三个示例分别来看这三种情况,并用 iostat、mpstat、pidstat 等工具,找出平均负载升高的根源。 测试准备工作 机器配置:2 CPU,8GB 内存。预先安装 stress 和 sysstat 包,如 apt install stress sysstat。 在这里,我先简单介绍一下 stress 和 sysstat。 * stress 是一个 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。 * 而 sysstat 包含了常用的 Linux 性能工具,用来监控和分析系统的性能。我们的案例会用到这个包的两个命令 mpstat 和 pidstat。 * **mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。** * **pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。** **此外,每个场景都需要你开三个终端,登录到同一台 Linux 机器中。** 先安装stress sysstat [root@VM-64-25-centos ~]# yum -y install stress sysstat rpm update sysstat [root@VM-64-25-centos ~]# wget https://rpmfind.
[Read More]
prometheus学习系列(七)
修改prometheus持久化参数
修改config文件,在里面添加一行. spec: retention: 365d 完整的实例,更新完成之后,记得apply一下. [root@VM-64-25-centos manifests]# cat prometheus-prometheus.yaml apiVersion: monitoring.coreos.com/v1 kind: Prometheus metadata: labels: prometheus: k8s name: k8s namespace: monitoring spec: alerting: alertmanagers: - name: alertmanager-main namespace: monitoring port: web image: quay.io/prometheus/prometheus:v2.17.2 nodeSelector: kubernetes.io/os: linux podMonitorNamespaceSelector: {} podMonitorSelector: {} replicas: 2 resources: requests: memory: 500Mi ruleSelector: matchLabels: prometheus: k8s role: alert-rules securityContext: fsGroup: 2000 runAsNonRoot: true runAsUser: 1000 additionalScrapeConfigs: name: additional-configs key: prometheus-additional.yaml retention: 7d #添加一行,持久化7天 storage: volumeClaimTemplate: spec: storageClassName: prometheus-cfs resources: requests: storage: 100Gi serviceAccountName: prometheus-k8s serviceMonitorNamespaceSelector: {} serviceMonitorSelector: {} version: v2.
[Read More]
ARTS第六周
ARTS第六周(2020年3月2日~2020年3月8日)
ARTS第五周
ARTS第五周(2020年1月13日~2020年1月19日)
读书
本周在读的书.
硅谷钢铁侠 (豆瓣) 时间管理在学习 变量2 (豆瓣)
Tip
prometheus持续学习 思维的认知提升和改变 Overview of all pages with the tag #prometheus - OpsNotes随思录
Share
1. https://medium.com/swlh/kubernetes-configmap-confuguration-and-reload-strategy-9f8a286f3a44ARTS第四周
ARTS第四周(2020年1月6日~2020年1月12日)
读书
本周在读的书.
硅谷钢铁侠 (豆瓣) 时间管理在学习
读书笔记
可以查看《津巴多时间观念》笔记
Tip
prometheus技巧在学习
Share
A DevOps Periodic Table of Critical Alert Monitoring System Integrations
https://itnext.io/kubernetes-monitoring-with-prometheus-in-15-minutes-8e54d1de2e13
ARTS第三周
ARTS第三周(2019年12月30日~2020年1月5日)
读书
本周在读书.
刻意练习 (豆瓣) 硅谷钢铁侠 (豆瓣) 请停止无效努力 (豆瓣) 已读完
读书笔记
可以查看《如何使用正确的方法快入进阶》笔记
Tip
学会在hexo中插入PDF文档
1. 安装hexo-pdf插件
npm install --save hexo-pdf
2. 在source目录下面和_posts同级的目录创建pdf目录把pdf文件放在里面
/Users/Learning/Learning materials/opsnotes/source
mkdir pdf
3. 在文章中引用
<br>
{% pdf /pdf/停止无效努力读书笔记.pdf %}
<br>
Share
1. 看了2篇英文文档
2019年总结,2020年打算
2019年总结,2020年打算
2019总结
前言
2019年的总结拖了好久,终于还是忍不住写下来了.2019年总体而言对自己的各方面是不满意的.
写作
基本没有写blog和公众号,虽然做了很多笔记,负分
工作
今年算马马虎虎,能做的基本做了,自己对自己的状态还是不满意
管理方面也没有得到多大提升
能力方面也是吃老本的样子,在突破阶段
读书
每个月大概读书有2本的样子.
技术书籍明显减少,多了一些科技人文方面的书籍,年初的时候给自己的目标定义是30本书,大概算只完成了70%的样子.
开发能力也没有多大的提升,动手能力还是比较差
生活
满意的事情:
太太怀孕了
健身能持久的坚持下来,算对自己最大的鼓励,不过第四季度松懈下来了.
喝酒变少了.
看待事情、生活更加理性了.
不满意的事情:
驾照没有考
旅游没有去
处理生活的琐碎还是不太得心应手
打游戏比较厉害浪费很多时间
2020展望
2020年要准备做的事情
个人方面:
健身持续不断的坚持下去.每周最少2次
2020年争取每个月读3本书
坚持学好L1和L2的课程.做好笔记
ARTS打卡能坚持下去
每个月能写2篇技术文章
把编程继续坚持学下去
坚持不打游戏
生活方面
多挣点奶粉钱
考驾照
出去旅游一次
能多陪家人
出去走一走
工作方面
能增加自己管理方面的突破
多参加几场技术大会
和业界的技术朋友多交流
ARTS第二周
ARTS第二周(2019年12月23日~29日)
读书
本周在读书.
读书笔记
可以查看《如何使用正确的方法快入进阶》笔记
Tip
MAC下面微信无法截图问题
解决catalina系统中微信或其他APP截图无法正常使用
1. 选择Security&privacy
2. 在隐私你们旋转,screen recording,选择wechat.重新登录就好.
Share
1. 看了2篇英文文档
Distributed Systems: When you should build them, and how to scale. A step-by-step guide.
https://medium.com/notbinary/the-twelve-factor-container-8d1edc2a49d4
ARTS第一周
ARTS第一周(2019年12月16日~22日)
Algorithm
Algorithm 链接: https://leetcode-cn.com/problems/add-two-numbers
Tip
[SuperUser] How to expand * on Bash command line
我是在Linux命令行上误操作时,发现通配符被自动扩展出来,于是通过搜索,找到了该“隐藏”的功能键:
输入命令ls *后,按键: + x + *,可以看到该目录下的文件列表,被扩展出来,可以继续进行编辑。
而在过去,我通常都需要手工对ls命令的结果进行选择和拷贝。
Share
分享一篇CSDN上的技术文章:
Hexo新建菜单(menu)存放归档文章
Hexo新建菜单(menu)存放归档文章
最近开始跟着耗子叔学“ARTS打卡”,想在首页上建一个名为“ARTS打卡”的的菜单,然后相关的“ARTS打卡”文章都放在该分类下。 生成post(文章)时默认生成categories配置项在项目目录下找到/scaffolds/post.md,添加文章的categories的配置,如下: ➜ opsnotes git:(master) ✗ cat scaffolds/post.md --- title: {{ title }} date: {{ date }} tags: --- ➜ opsnotes git:(master) ✗ 写文章时,配置 categories下面我开始写一篇关于 Python 的文章,文章里面配置categories. ➜ opsnotes git:(master) ✗ cat source/_posts/ARTS-Weekly/ARTS第一周\(2019年12月16日\~22日\).md --- title: ARTS第一周(2019年12月16日~22日) tags: ARTS打卡 categories: ARTS打卡 date: 2019-12-19 13:42:23 --- ➜ opsnotes git:(master) ✗ 使用“hexog g”更新之后,会生成文件.这时你会发现/public/categories/文件夹下,已经生成了“ARTS打卡”的文件夹. 首页显示ARTS打卡菜单. 这里就是要在博客首页上显示 python 菜单的时候了,首先打开你主题的配置文件/themes/cactus/_config.yml(我这里是用的cactus).找到menu,这里添加一行. nav: home: / articles: /archives/ ARTS: /categories/ARTS打卡/ ###新添加的 projects: https://github.com/opsnotes about: /about/ search: /search/ 菜单名称配置 上面的步骤做完以后,如果你着急刷新页面看了效果,就会看到新菜单的名称是menu.python,显然不是我们想要的,那就继续往下看首先查看项目目录下的/_config.yml的language配置,我的是这样的 ➜ opsnotes git:(master) ✗ cat themes/cactus/languages/zh-CN.
[Read More]
kubernetes dashboard install
kubernetes dashboard install
install dashboard
1. 参考资料[GitHub - kubernetes/dashboard: General-purpose web UI for Kubernetes clusters](https://github.com/kubernetes/dashboard)
2. install dashboard
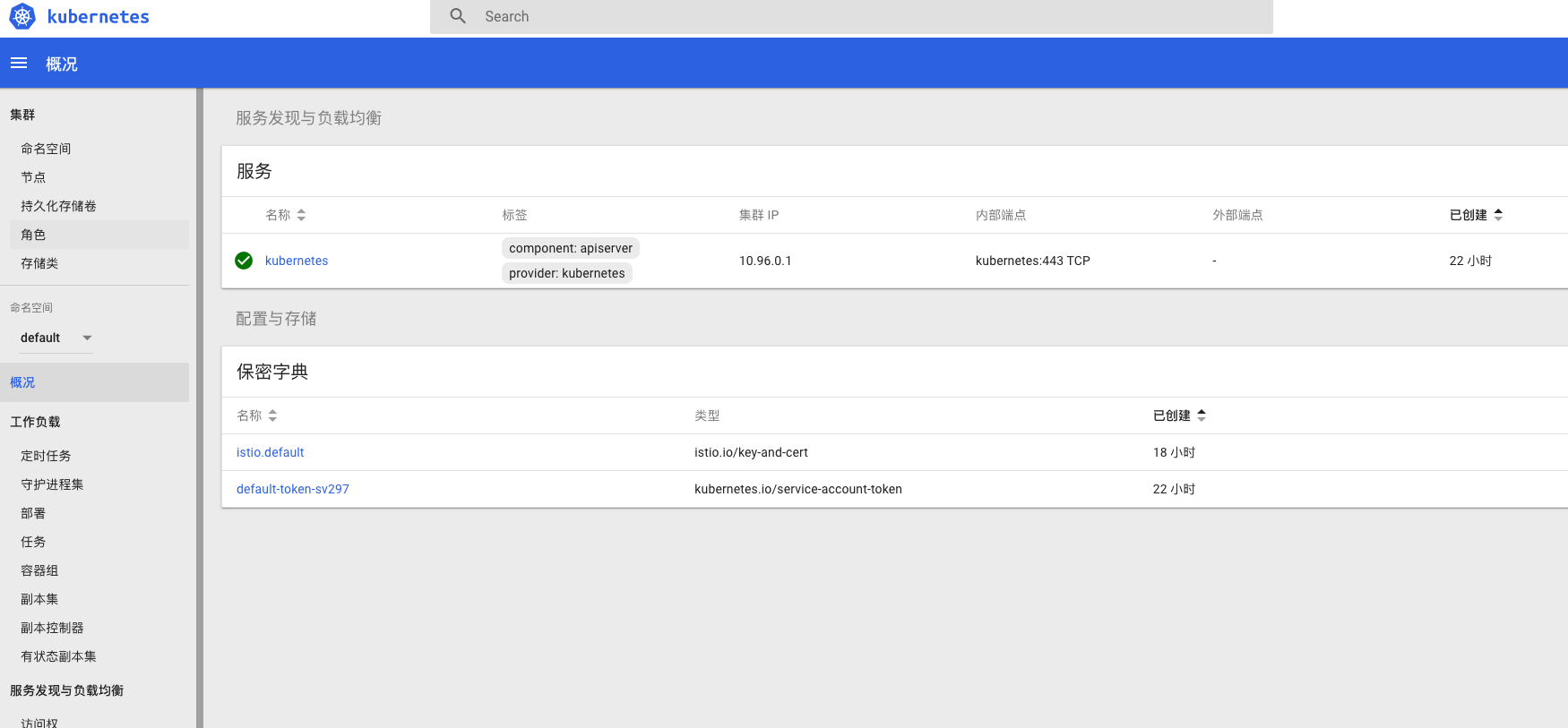
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
3. 启动proxy
kubectl proxy
如果启动报错,查看pod是否运行
4. 访问url
http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/.
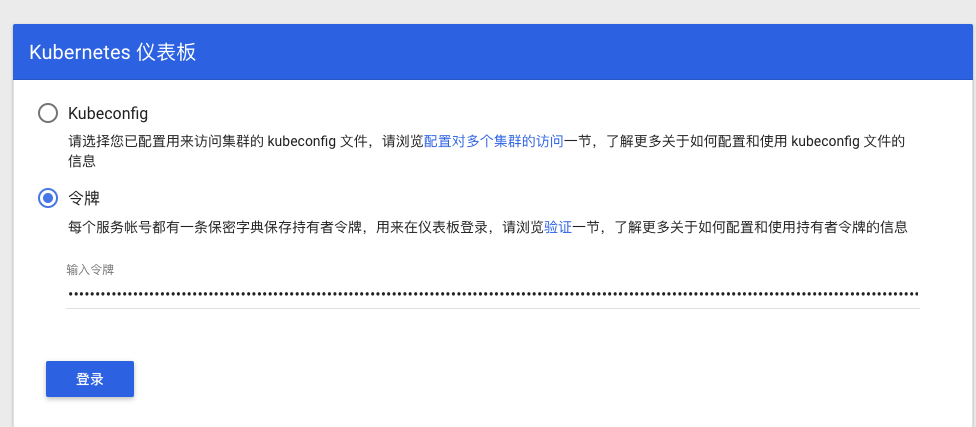
5. 生成token,参考资料https://github.com/kubernetes/dashboard/blob/master/docs/user/access-control/creating-sample-user.md
kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk ‘{print $1}’)
6. 在dashboar界面输入token即可