记一次惨痛的zabbix数据库分表
最近负责公司的zabbix项目,由于前期缺少整体性能架构的规划,导致后期出一系列的问题,玩zabbix的兄弟都知道,zabbix最大的瓶颈本身不在zabbix服务,而在mysql数据库的压力上,因此,优化zabbix其实就是优化zabbix的配置以及zabbix的mysql了;
Zabbix 数据库常见的优化处理方法有两种:
01. 优化数据库,对数据库进行分表处理;
02. 清空数据库中的history, history_uint表;
在接下来的方案我们就mysql数据库分表来进行优化;
具体思路:
1. 首先下载脚本
https://github.com/itnihao/zabbixdbpartitioning
感谢hao哥提供脚本以及帮助。
2. 前期准备工作,安全起见最好安装screen,也不怕程序卡死,关于screen的用法请参考http://www.kwx.gd/CentOSApp/CentOS-screen.html
关闭zabbix的邮件报警,也可以关闭zabbix server服务,mysql本身会锁表
3. 在screen模式下运行脚本,
在这里需要注意的是,如果你的数据库特别大,最好先备份,然后在修改脚本,然后分表,在修改脚本的时候需要注意的几个地方我这里先列出来下,如下:
首先修改zabbix 数据库和密码 默认情况下是都是zabbix 如果你的也是这样的话,那么不用修改,
然后修改配置文件的路径,根据自己的自定义的路径来修改脚本的路径
如果手动备份了那么关闭脚本中备份.
4. 然后来查看是否创建完成;
具体实施:
1. 首先在安装部署之前,来查看两张图片,然后我们就知道压力怎么样了,
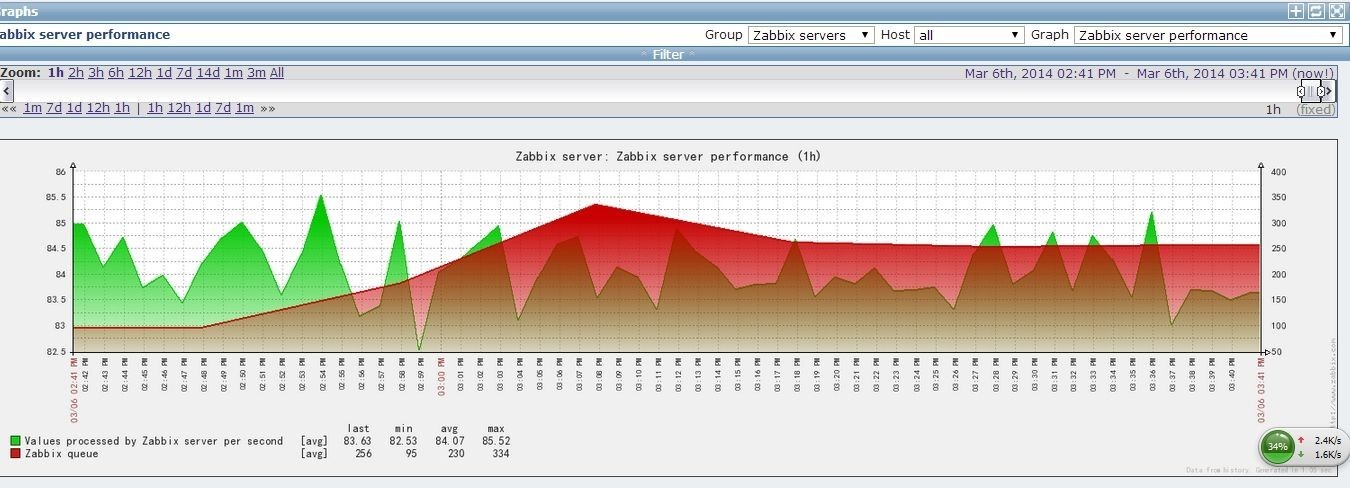
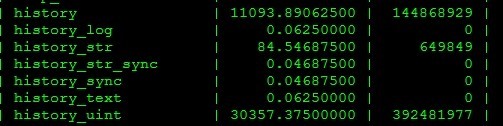
2. 切记记得备份,关于备份就不在这里列出来了,使用mysqldump来完成备份.关闭zabbix服务器;
完整导出数据库备份,
mysqldump -uroot -p zabbix > /www/zabbix.sql
导出数据库结构不导出数据:
mysqldump --opt -d zabbix -uroot -p > zabbix.biao.sql
关闭zabbix服务:
/etc/rc.d/init.d/zabbix-server stop
3. 执行脚本,在执行脚本之前,我们先创建两张表, history_bak和history_uint_bak,然后我们重命名原来的两张表history和history_uint两张表;然后把创建的两张表变成原来的,这样表中就没有数据了.如下:
创建表:关于创建,可以到处zabbix数据库的表结构,然后找到这个表就可以,还好这两张表没有依赖关系。
CREATE TABLE `history_bak` (
`itemid` bigint(20) unsigned NOT NULL,
`clock` int(11) NOT NULL DEFAULT '0',
`value` double(16,4) NOT NULL DEFAULT '0.0000',
`ns` int(11) NOT NULL DEFAULT '0',
KEY `history_1` (`itemid`,`clock`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
CREATE TABLE `history_uint_bak` (
`itemid` bigint(20) unsigned NOT NULL,
`clock` int(11) NOT NULL DEFAULT '0',
`value` bigint(20) unsigned NOT NULL DEFAULT '0',
`ns` int(11) NOT NULL DEFAULT '0',
KEY `history_uint_1` (`itemid`,`clock`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
重命名表:
rename table history to history_bak_14_03_08;
rename table history_bak to history;
rename table history_uint to history_uint_bak_14_03_08;
rename table history_uint_bak to history_uint;
4. 然后来执行脚本;
bash -x partitiontables.sh,可以根据提示来选择Y/N
因为我是代bug模式输出的脚本,输出比较多,我在这里截几张重要的图片,大家已做参考:
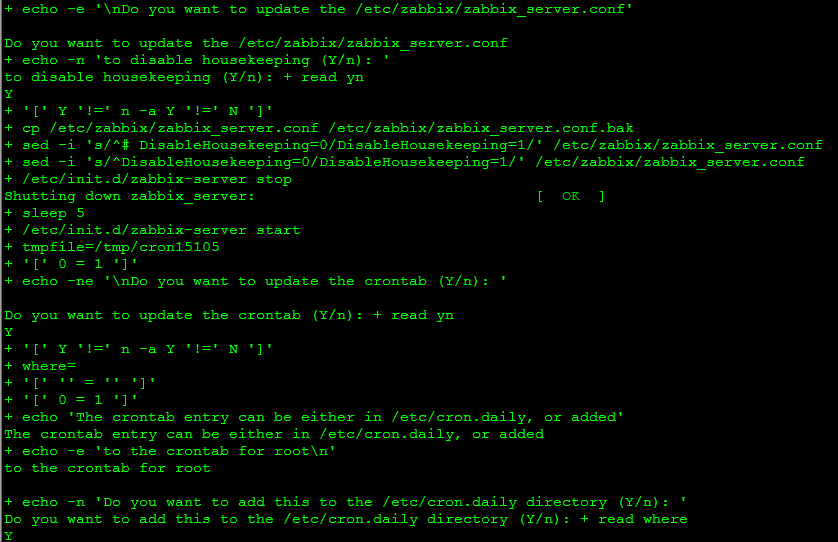
5. 完成之后我们可以查看数据是否来看有没有成功
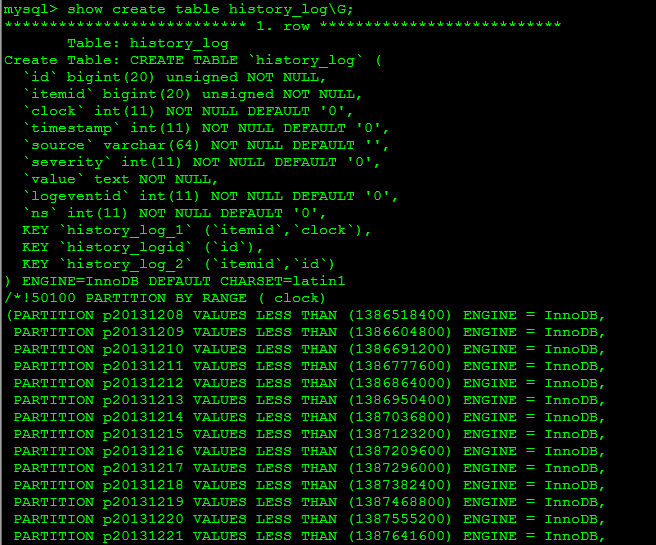
生成的任务计划脚本路径:
cat /etc/cron.daily/zabbixhousekeeping
记得要在脚本中配置邮件,因为在我们的案例总我们使用使用的是mutt+msmtp 脚本如下:
[root@zabbix-server-01 ~]# cat /usr/local/zabbix/cron.d/housekeeping.sh
#!/bin/bash
MAILTO=431054426@qq.com
tmpfile=/tmp/housekeeping$$
date >$tmpfile
/usr/bin/mysql --skip-column-names -B -h localhost -u zabbix -pzabbix zabbix -e "CALL create_zabbix_partitions();" >>$tmpfile 2>&1
/usr/bin/mutt -s "Zabbix MySql Partition Housekeeping" $MAILTO <$tmpfile
rm -f $tmpfile
[root@zabbix-server-01 ~]#
然后会收到报警邮件
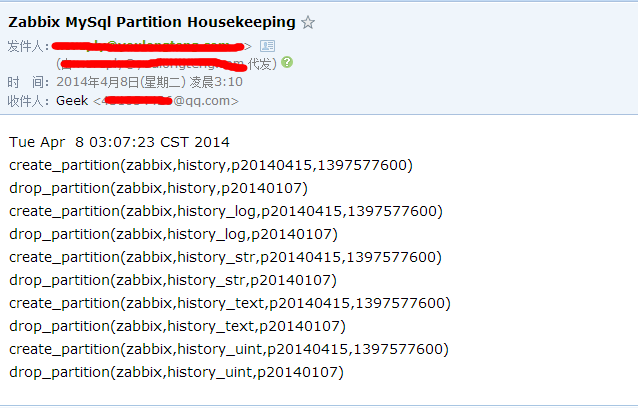
也许很多人搞不明白为什么我要重命名这两张表,然后在执行脚本来这样做呢?更怕历史记录找不见呢?我做过测试,如果在不重命名history两张表的情况下,两天估计都分表完成, 我做过测试,我的history有8G大小,我用8个小时都没有分表完成,更何况history_uint这个快30G的表,虽然这样做就是无法看到历史数据,我们可以完全搭建个LNMP或者LAMP,创建数据库,在创建的数据库上导入这个我们备份的mysql来查看以前的历史记录。或者在zabbxi server机器上做个虚拟目录,数据库指定到备份的服务器上;虽然这样有点蛋疼但是这也是我目前了解最快的不丢失数据的办法,也可以解决以后塞满表的情况!
如果不要zabbix的历史记录那么就很简单的来做了.如下:
use zabbix;
truncate table history;
optimize table history;
truncate table history_str;
truncate table history_uint;
参考文章:https://www.zabbix.org/wiki/Docs/howto/mysql_partition